Thông tin liên hệ
- 036.686.3943
- admin@nguoicodonvn2008.info
Trong nhiều năm, các nguyên tắc xây dựng mô hình ngôn ngữ lớn (LLM) chủ yếu tập trung vào việc tối ưu chi phí huấn luyện. Tuy nhiên, trong các ứng dụng thực tế, chi phí suy luận (inference) mới là yếu tố chi phối lâu dài — đặc biệt khi các hệ thống hiện đại ngày càng phụ thuộc vào việc “lấy nhiều mẫu suy luận” để cải thiện độ chính xác.
Chính khoảng trống này đã thúc đẩy sự ra đời của một hướng tiếp cận mới mang tên Train-to-Test (T2) scaling — một framework giúp tối ưu toàn bộ ngân sách tính toán từ giai đoạn huấn luyện đến triển khai.
Trong thế giới LLM, scaling laws (quy luật mở rộng) đóng vai trò như kim chỉ nam. Một mặt, chúng hướng dẫn cách phân bổ tài nguyên khi huấn luyện mô hình; mặt khác, chúng định hình cách sử dụng tài nguyên khi triển khai, chẳng hạn như cho phép mô hình “suy nghĩ lâu hơn” hoặc tạo nhiều đáp án để chọn ra kết quả tốt nhất.
Vấn đề nằm ở chỗ: hai hệ quy luật này được phát triển gần như độc lập, dù trên thực tế chúng có liên hệ chặt chẽ với nhau.
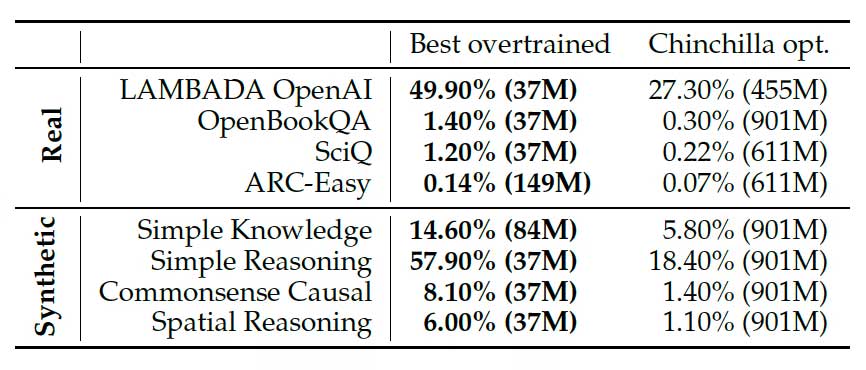
Ví dụ, quy tắc nổi tiếng Chinchilla đề xuất tỷ lệ tối ưu giữa số tham số và dữ liệu huấn luyện (khoảng 20 token cho mỗi tham số). Nhưng trong thực tế, nhiều mô hình hiện đại như Llama hay Gemma lại cố tình “huấn luyện quá mức” (overtrain) các mô hình nhỏ với lượng dữ liệu khổng lồ — đi ngược lại quy tắc này.
Lý do rất đơn giản: khi chi phí mỗi lần suy luận trở nên đắt đỏ (do mô hình lớn), việc lặp lại nhiều lần để tăng độ chính xác sẽ trở nên không khả thi. Ngược lại, các mô hình nhỏ nhưng được huấn luyện kỹ có thể cho phép lặp lại suy luận nhiều lần với chi phí thấp hơn rất nhiều.
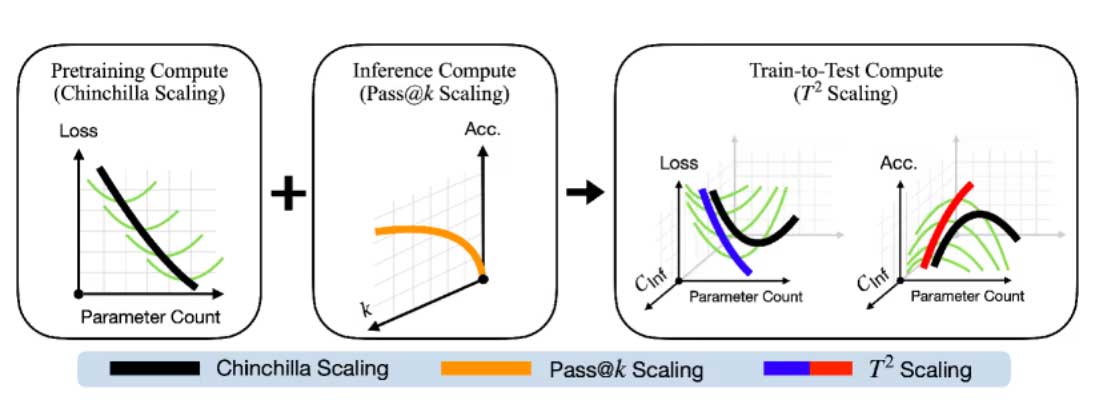
Để giải quyết sự rời rạc này, các nhà nghiên cứu đã đề xuất Train-to-Test (T2) scaling laws , một mô hình kết hợp cả ba yếu tố quan trọng vào cùng một phương trình:
Kích thước mô hình
Lượng dữ liệu huấn luyện
Số lần lấy mẫu suy luận khi triển khai
Thay vì tối ưu từng phần riêng lẻ, T2 xem toàn bộ quá trình như một hệ thống thống nhất. Nó không chỉ tính chi phí huấn luyện mà còn tính cả chi phí lặp lại khi suy luận — yếu tố thường bị bỏ qua trước đây.
Điểm thú vị là framework này có thể dự đoán hiệu suất của mô hình dựa trên xác suất thành công sau nhiều lần thử (pass@k), thay vì chỉ dựa vào chỉ số lỗi trong huấn luyện. Điều này phản ánh sát hơn cách AI được sử dụng trong thực tế.
Khi áp dụng T2 scaling vào thực nghiệm với hơn 100 mô hình khác nhau, kết quả cho thấy một điều khá bất ngờ:
Trong nhiều trường hợp, chiến lược tối ưu không phải là xây dựng mô hình lớn hơn, mà thay vào đó là sử dụng mô hình quy mô nhỏ hơn, huấn luyện với nhiều dữ liệu hơn, và tận dụng chi phí tiết kiệm được để tăng số lần suy luận
Cách tiếp cận này giúp các mô hình nhỏ nhưng “luyện kỹ” vượt qua các mô hình lớn trong nhiều bài toán — đặc biệt là các tác vụ yêu cầu suy luận phức tạp.
Nói cách khác, hiệu năng không còn phụ thuộc tuyệt đối vào kích thước mô hình, mà phụ thuộc vào cách bạn phân bổ ngân sách tính toán một cách thông minh.
Tuy nhiên, không phải mọi ứng dụng đều hưởng lợi từ T2 scaling. Framework này đặc biệt hiệu quả với các tác vụ yêu cầu suy luận nhiều bước như lập trình, giải toán hoặc các workflow agent phức tạp.
Ngược lại, với các ứng dụng thiên về kiến thức tĩnh như chatbot thông thường, lợi ích có thể không rõ rệt.
Điều này đặt ra một nguyên tắc quan trọng: lựa chọn chiến lược scaling phải dựa trên bản chất bài toán, không phải xu hướng chung của ngành.
Một điểm đáng chú ý là việc triển khai T2 scaling không đòi hỏi công nghệ quá phức tạp. Các kỹ thuật như KV caching (lưu cache ngữ cảnh đã xử lý) có thể giúp giảm đáng kể chi phí khi lặp lại suy luận.
Tuy nhiên, việc “overtraining” cũng có những đánh đổi. Các mô hình được huấn luyện quá mức có thể khó fine-tune hơn và đòi hỏi lượng dữ liệu rất lớn — thậm chí có nguy cơ chạm đến “giới hạn dữ liệu” khi nguồn dữ liệu chất lượng cao không còn đủ.
Dù vậy, trong bối cảnh chi phí của các mô hình frontier ngày càng cao, T2 scaling mang lại một hướng đi mới mang tính “dân chủ hóa”: cho phép nhiều tổ chức nhỏ hơn xây dựng hệ thống AI mạnh mà không cần ngân sách khổng lồ.
Train-to-Test scaling không chỉ là một cải tiến kỹ thuật, mà là một cách nhìn mới về cách xây dựng AI.
Thay vì tập trung tối đa vào mô hình lớn, cách tiếp cận này đặt trọng tâm vào việc phân bổ tài nguyên một cách thông minh trên toàn bộ vòng đời AI — từ huấn luyện đến suy luận.
Trong tương lai, khi các hệ thống AI ngày càng phụ thuộc vào reasoning và agent workflows, những chiến lược như T2 có thể trở thành tiêu chuẩn mới, thay thế cho tư duy “càng lớn càng tốt” vốn đã thống trị ngành trong nhiều năm.
Nguồn tin: Quantrimang.com:
Ý kiến bạn đọc
Những tin mới hơn
 Prompt hệ thống, thiết kế và quản lý vai trò (23/04/2026)
Prompt hệ thống, thiết kế và quản lý vai trò (23/04/2026)  Chào ngày mới thứ 6, lời chúc thứ 6 vui vẻ (23/04/2026)
Chào ngày mới thứ 6, lời chúc thứ 6 vui vẻ (23/04/2026)  5 script Python nâng cao giúp kiểm tra dữ liệu chính xác hơn (23/04/2026)
5 script Python nâng cao giúp kiểm tra dữ liệu chính xác hơn (23/04/2026)  Tạo bài thuyết trình chuyên nghiệp với Prezi AI (23/04/2026)
Tạo bài thuyết trình chuyên nghiệp với Prezi AI (23/04/2026)  Hướng dẫn tạo slide bằng Faces app AI (23/04/2026)
Hướng dẫn tạo slide bằng Faces app AI (23/04/2026)  Thiết kế prompt nâng cao (23/04/2026)
Thiết kế prompt nâng cao (23/04/2026)  Mẫu prompt luyện kỹ thuật shadowing tiếng Anh bằng Gemini (23/04/2026) OpenClaw và chia sẻ skill trong Cowork (23/04/2026)
Mẫu prompt luyện kỹ thuật shadowing tiếng Anh bằng Gemini (23/04/2026) OpenClaw và chia sẻ skill trong Cowork (23/04/2026)  Xây dựng thư viện prompt của bạn (26/04/2026)
Xây dựng thư viện prompt của bạn (26/04/2026)  Hướng dẫn tạo slide thuyết trình trên TeraBox (26/04/2026)
Hướng dẫn tạo slide thuyết trình trên TeraBox (26/04/2026) Những tin cũ hơn
 API Trigger: Stripe Webhook để soạn thảo email (22/04/2026)
API Trigger: Stripe Webhook để soạn thảo email (22/04/2026)  Prompt biến Gemini thành trợ lý học tiếng Anh cho người đi làm (22/04/2026)
Prompt biến Gemini thành trợ lý học tiếng Anh cho người đi làm (22/04/2026)  Sử dụng các plugin tích hợp sẵn trong Claude Cowork (22/04/2026)
Sử dụng các plugin tích hợp sẵn trong Claude Cowork (22/04/2026)  Tạo kế hoạch giảng dạy tích hợp AI trên NotebookLM (22/04/2026)
Tạo kế hoạch giảng dạy tích hợp AI trên NotebookLM (22/04/2026)  Hướng dẫn tạo mô hình 3D cho môn Khoa học tự nhiên (22/04/2026)
Hướng dẫn tạo mô hình 3D cho môn Khoa học tự nhiên (22/04/2026)  Bảo vệ an toàn cho code của bạn: Bảo mật và quyền hạn (21/04/2026)
Bảo vệ an toàn cho code của bạn: Bảo mật và quyền hạn (21/04/2026) 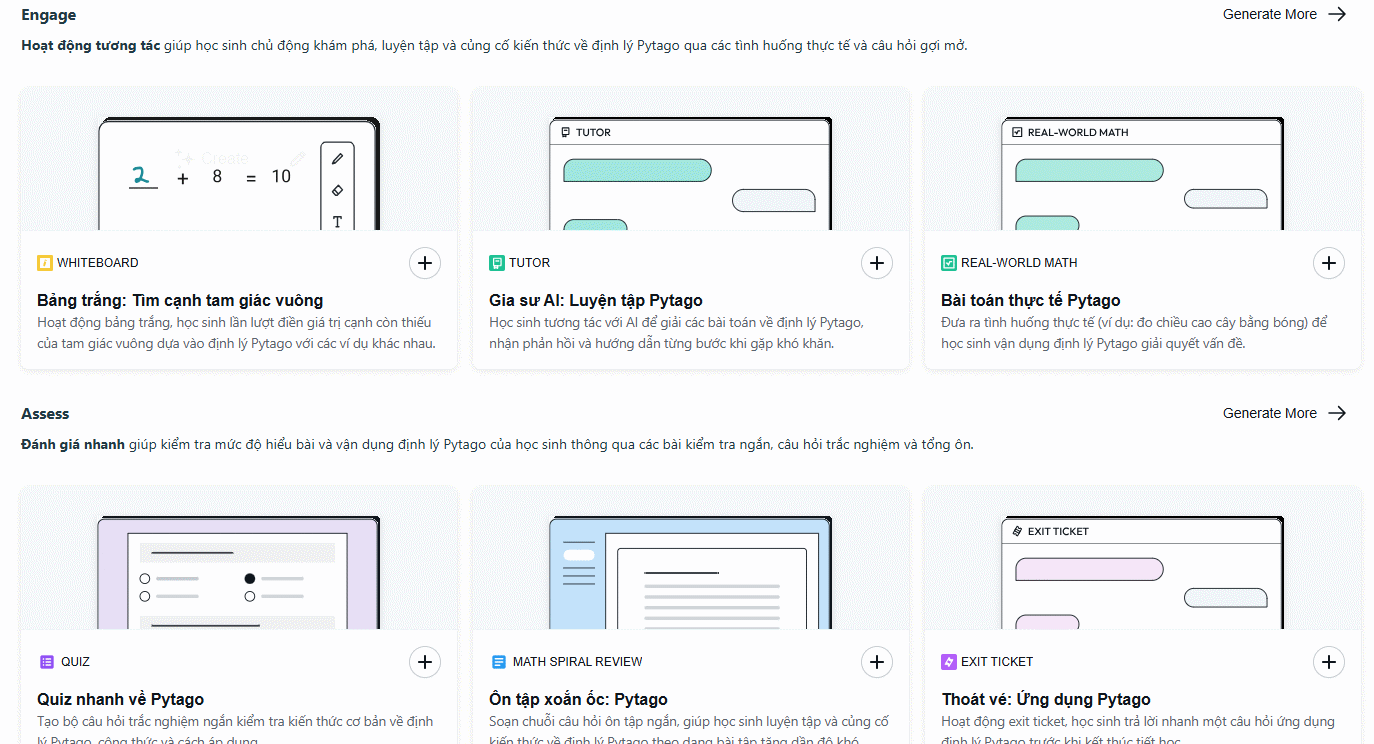 Hướng dẫn tạo trợ lý học tập AI Brisk cho học sinh (21/04/2026)
Hướng dẫn tạo trợ lý học tập AI Brisk cho học sinh (21/04/2026) 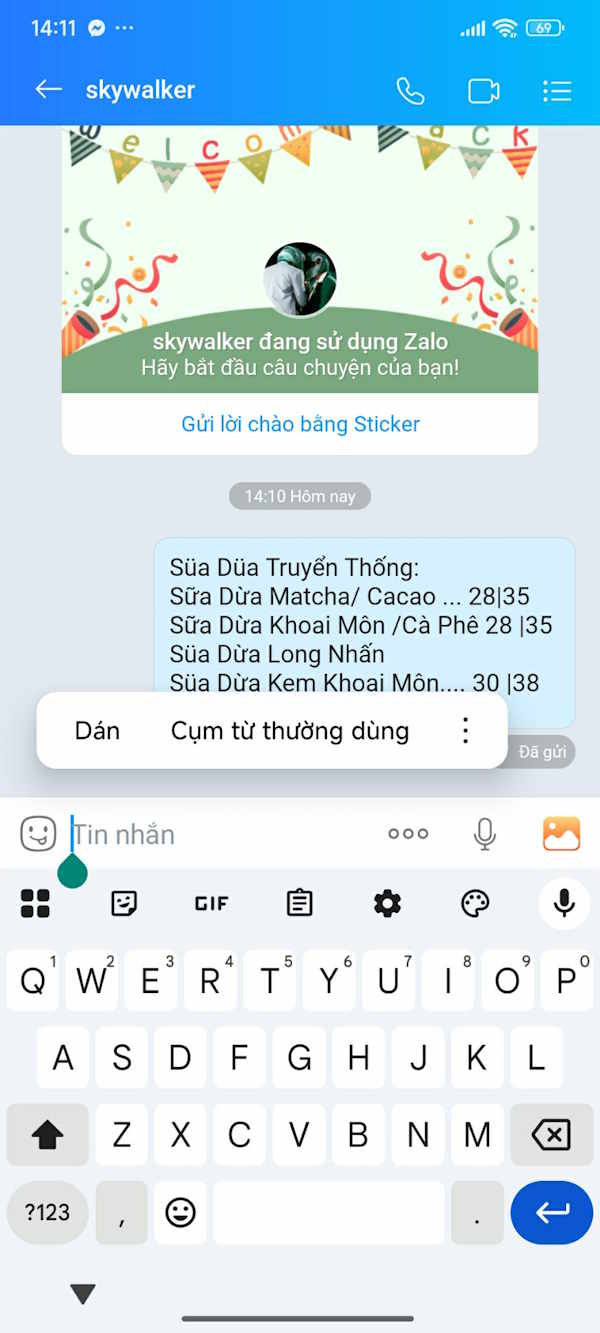 Cách copy chữ trong ảnh thành tin nhắn trên Zalo AI (21/04/2026)
Cách copy chữ trong ảnh thành tin nhắn trên Zalo AI (21/04/2026) 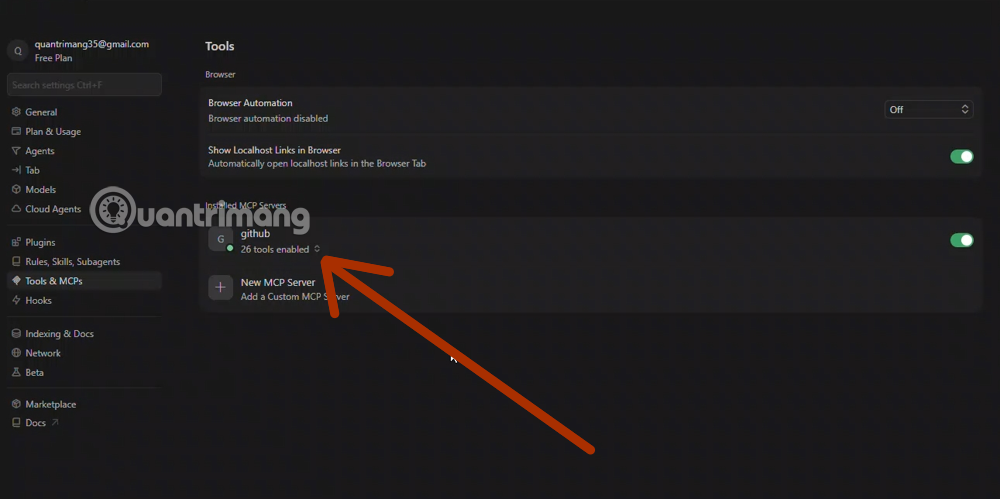 Hướng dẫn tạo slide bài giảng bằng Brisk AI (21/04/2026)
Hướng dẫn tạo slide bài giảng bằng Brisk AI (21/04/2026)  API Trigger: Stripe Webhook để soạn thảo email (21/04/2026)
API Trigger: Stripe Webhook để soạn thảo email (21/04/2026)  Nên chọn giao diện nào cho AI Coding Agent? Kinh nghiệm tối ưu năng suất làm việc với AI
Nên chọn giao diện nào cho AI Coding Agent? Kinh nghiệm tối ưu năng suất làm việc với AI
 5 tài liệu miễn phí giúp học AI Agent từ cơ bản đến nâng cao
5 tài liệu miễn phí giúp học AI Agent từ cơ bản đến nâng cao
 Karaoke chảng trai dễ thương- (Beat Midi )
Karaoke chảng trai dễ thương- (Beat Midi )
 3 việc bạn chỉ có thể làm với ChatGPT Work, còn ChatGPT thông thường thì không
3 việc bạn chỉ có thể làm với ChatGPT Work, còn ChatGPT thông thường thì không
 Hướng dẫn dùng tính năng "Đã lên lịch" trên Meta AI
Hướng dẫn dùng tính năng "Đã lên lịch" trên Meta AI
 Cách tắt overview AI trong phụ đề video TikTok
Cách tắt overview AI trong phụ đề video TikTok
 TOP trợ lý AI cho CEO, quản lý và founder tốt nhất
TOP trợ lý AI cho CEO, quản lý và founder tốt nhất
 6 prompt Gemini biến ảnh chân dung thành sticker pastel
TOP trợ lý AI cho CEO, quản lý và founder tốt nhất
6 prompt Gemini biến ảnh chân dung thành sticker pastel
TOP trợ lý AI cho CEO, quản lý và founder tốt nhất
 TOP công cụ AI quản lý chiến dịch PPC tốt nhất
TOP công cụ AI quản lý chiến dịch PPC tốt nhất
 8 website chuyển văn bản thành giọng nói tốt nhất
8 website chuyển văn bản thành giọng nói tốt nhất
 Tổng quan về Microsoft IQ cho agent trong Copilot Studio
Tổng quan về Microsoft IQ cho agent trong Copilot Studio
 Prompt thiết kế banner khai giảng năm học mới các cấp học
Prompt thiết kế banner khai giảng năm học mới các cấp học
 Hướng dẫn tạo emoji AI cho thiết kế Canva
Hướng dẫn tạo emoji AI cho thiết kế Canva
 Vì sao AI Agent vẫn cần Machine Learning truyền thống?
Vì sao AI Agent vẫn cần Machine Learning truyền thống?
 10 phần mềm tạo nhạc bằng AI tốt nhất năm 2026
10 phần mềm tạo nhạc bằng AI tốt nhất năm 2026
 Llama vs ChatGPT: Nền tảng AI nào tốt hơn?
Llama vs ChatGPT: Nền tảng AI nào tốt hơn?
 AI Voice Agent là gì? Tìm hiểu cách thức hoạt động của trợ lý thoại AI
AI Voice Agent là gì? Tìm hiểu cách thức hoạt động của trợ lý thoại AI
 Hướng dẫn tạo câu hỏi trắc nghiệm trên Gemini
Hướng dẫn tạo câu hỏi trắc nghiệm trên Gemini
 TOP trang web tạo ảnh AI tốt nhất
TOP trang web tạo ảnh AI tốt nhất