Thông tin liên hệ
- 036.686.3943
- admin@nguoicodonvn2008.info
Ôn tập: Trong bài học trước, bạn đã tự động hóa quá trình xử lý dữ liệu với pandas — đọc, làm sạch và chuyển đổi bảng tính. Bây giờ, hãy lấy dữ liệu từ chính web: Trích xuất thông tin từ các trang web khi không có API hoặc công cụ tải xuống nào khả dụng.
Web scraping biến các trang web không có cấu trúc thành dữ liệu có cấu trúc. Theo dõi giá cả, tổng hợp danh sách việc làm, theo dõi tin tức, phân tích cạnh tranh — nếu dữ liệu có trên một trang web, Python có thể trích xuất nó.
📍 Nơi dán: Mở ChatGPT (chat.openai.com), Claude (claude.ai) hoặc Gemini (gemini.google.com) và bắt đầu một cuộc trò chuyện mới.
pip install requests beautifulsoup4 lxml📋 Cách sao chép prompt này: Nhấp chuột vào bất kỳ đâu bên trong khối màu xám, nhấn Cmd+A rồi Cmd+C (Mac) hoặc Ctrl+A rồi Ctrl+C (Windows). Hoặc sử dụng biểu tượng sao chép xuất hiện.
👀 Những gì bạn sẽ thấy: Trong vòng vài giây, AI sẽ trả về một câu trả lời có cấu trúc dựa vào prompt ở trên. Hãy đọc kỹ và coi đó là bản nháp, không phải câu trả lời cuối cùng.
| Thư viện | Mục đích |
requests | Tải xuống các trang web (yêu cầu HTTP) |
BeautifulSoup | Phân tích cú pháp HTML và trích xuất dữ liệu |
lxml | Trình phân tích cú pháp HTML nhanh (được BeautifulSoup sử dụng) |
Viết một công cụ Web scraping bằng Python sử dụng thư viện requests và BeautifulSoup để: (1) Truy xuất một trang web tại một URL cho trước, (2) Trích xuất tất cả tên sản phẩm và giá cả từ trang đó (giả sử sản phẩm nằm trong các phần tử có lớp "product" chứa thẻ h2 cho tên và thẻ span.price cho giá), (3) Lưu dữ liệu dưới dạng CSV với các cột: tên, giá, URL, ngày trích xuất, (4) Xử lý: lỗi HTTP (mã trạng thái không phải 200), lỗi kết nối, thiếu phần tử (một số sản phẩm có thể không có giá). Bao gồm các tiêu đề phù hợp với chuỗi User-Agent.| Thao tác | Code | Chức năng của nó |
| Tìm một yếu tố |
| Phần tử khớp đầu tiên |
| Tìm tất cả các phần tử |
| Tất cả các yếu tố phù hợp |
| Lấy văn bản |
| Nội dung văn bản, đã loại bỏ khoảng trắng |
| Lấy thuộc tính |
| Giá trị thuộc tính HTML |
| Bộ chọn CSS |
| Cú pháp bộ chọn CSS |
| Điều hướng |
| Di chuyển qua DOM |
Khi bạn không biết cấu trúc HTML, AI có thể giúp đỡ:
Prompt AI:
Đây là HTML của một trang liệt kê sản phẩm: [DÁN HTML]. Tôi cần trích xuất: tên sản phẩm, giá, xếp hạng và URL sản phẩm. Xác định các bộ chọn CSS hoặc mẫu BeautifulSoup để trích xuất từng phần dữ liệu. Cho tôi xem một code snippet hoạt động.Đây là lúc AI tỏa sáng — việc phân tích cấu trúc HTML và tìm ra các bộ chọn phù hợp là công việc tốn thời gian đối với con người nhưng lại rất dễ dàng đối với AI.
| Thực hành | Lý do | Cách thực hiện |
Kiểm tra robots.txt | Các trang web quy định rõ những dữ liệu nào được phép thu thập |
|
Tôn trọng giới hạn tốc độ | Đừng làm quá tải server! |
|
Tự giới thiệu bản thân | Hãy để chủ sở hữu trang web liên hệ với bạn | Thiết lập User-Agent: MyProjectName (email@example.com) |
Phản hồi cache | Không yêu cầu lại cùng một trang | Lưu HTML cục bộ, kiểm tra trước khi gửi yêu cầu |
Kiểm tra API | API đáng tin cậy và được cho phép sử dụng rộng rãi hơn | Tìm kiếm site.com/api hoặc tài liệu dành cho nhà phát triển |
Kiểm tra điều khoản dịch vụ | Một số trang web cấm rõ ràng việc thu thập dữ liệu tự động | Hãy đọc Điều khoản dịch vụ trước khi xây dựng công cụ thu thập dữ liệu |
Viết một trình thu thập dữ liệu có nhận biết phân trang bằng thư viện requests và BeautifulSoup: (1) Bắt đầu từ URL của trang danh sách sản phẩm, (2) Trích xuất dữ liệu từ tất cả các sản phẩm trên trang, (3) Tìm và theo liên kết "trang tiếp theo", (4) Dừng lại khi không có trang tiếp theo, (5) Thêm độ trễ ngẫu nhiên 2 giây giữa các trang, (6) Lưu kết quả tăng dần vào CSV sau mỗi trang (an toàn khi tiếp tục), (7) Theo dõi tiến độ: in số trang, tổng số mục đã thu thập, (8) Nếu một trang trả về 0 mục, hãy ghi lại cảnh báo nhưng vẫn tiếp tục. Chấp nhận URL bắt đầu và đường dẫn CSV đầu ra làm đối số.| Tình huống | Giải pháp thay thế tốt hơn |
| Trang web này có API công khai | Hãy sử dụng API — nhanh hơn, đáng tin cậy hơn và được cho phép rõ ràng |
| Dữ liệu nằm sau thông tin đăng nhập | Có thể vi phạm Điều khoản dịch vụ — hãy kiểm tra trước |
| Dữ liệu là nội dung có bản quyền | Rủi ro pháp lý — vui lòng tham khảo Điều khoản dịch vụ và luật áp dụng |
| Trang web chặn tất cả các công cụ thu thập dữ liệu | Họ đã nói rõ là không rồi — hãy tôn trọng điều đó |
| Dữ liệu được cập nhật theo thời gian thực | API hoặc websocket sẽ phù hợp hơn |
✅ Kiểm tra nhanh: Bạn đang trích xuất dữ liệu từ một trang nhưng requests.get() trả về HTML không chứa dữ liệu bạn thấy trên trình duyệt. Trang load dữ liệu thông qua JavaScript sau khi HTML ban đầu được load. Bạn cần gì?
Câu trả lời: Đối với các trang được hiển thị bằng JavaScript, `requests` + `BeautifulSoup` không thể hoạt động vì chúng chỉ thấy HTML ban đầu trước khi JavaScript chạy. Các lựa chọn: (1) Kiểm tra xem JavaScript có lấy dữ liệu từ API hay không — sử dụng tab DevTools Network của trình duyệt để tìm endpoint API, sau đó gọi trực tiếp bằng `requests`. Đây là cách tiếp cận tốt nhất. (2) Sử dụng Selenium hoặc Playwright để hiển thị trang bằng trình duyệt thực. Cách này chậm hơn nhưng hoạt động với bất kỳ trang nào.
Một trình trích xuất dữ liệu được cấu trúc tốt sẽ tách biệt các vấn đề:
✏️ Cách điền thông tin chi tiết của bạn: Thay thế mỗi [] và trình giữ chỗ trong ngoặc bằng các thông tin cụ thể từ tình huống thực tế của bạn. Đầu vào mơ hồ sẽ tạo ra đầu ra mơ hồ — hãy cụ thể.
👀 Những gì bạn sẽ thấy: Trong vòng vài giây, AI sẽ trả về một phản hồi có cấu trúc dựa vào prompt ở trên. Hãy đọc kỹ và coi đó là bản nháp, không phải câu trả lời cuối cùng.
📌 Cách sử dụng kết quả: Lưu phản hồi vào file Notes. Chọn gợi ý có hiệu quả cao nhất và thực hiện nó trong tuần này — đừng cố gắng làm tất cả cùng một lúc.
⚠️ Nếu kết quả không ổn: Nếu các gợi ý có vẻ chung chung, hãy dán nội dung sau: "Hãy cụ thể hơn với ngữ cảnh thực tế của tôi. Bỏ qua những lời khuyên chung chung." Nếu nó bỏ qua các chi tiết quan trọng bạn đã cung cấp, hãy hỏi: "Bạn đã bỏ sót [X] trong ngữ cảnh của tôi — hãy thực hiện lại với điều đó làm ràng buộc chính."
Python
# Cấu trúc trình thu thập dữ liệu của bạn thành các hàm rõ ràng:
# 1. fetch_page(url) - xử lý các yêu cầu HTTP, thử lại, độ trễ
# 2. parse_products(html) - trích xuất dữ liệu từ HTML
# 3. save_results(data, filepath) - ghi vào CSV/Excel
# 4. main() - điều phối luồng, xử lý phân trangPrompt AI cho cấu trúc:
Tái cấu trúc trình thu thập dữ liệu của tôi thành các hàm rõ ràng: (1) fetch_page() xử lý việc thử lại (3 lần), độ trễ và ghi nhật ký lỗi, (2) parse_page() trích xuất dữ liệu và trả về một danh sách các từ điển, (3) save_data() thêm vào CSV một cách tăng dần, (4) main() xử lý phân trang và theo dõi tiến độ. Thêm flag --test để chỉ thu thập dữ liệu từ trang đầu tiên để kiểm tra.Luôn luôn thu thập dữ liệu một cách có đạo đức: kiểm tra robots.txt, thêm độ trễ giữa các yêu cầu (1-3 giây), đặt tiêu đề User-Agent trung thực và kiểm tra xem API có tồn tại trước hay không — việc thu thập dữ liệu quá mức có thể khiến IP của bạn bị chặn và có thể vi phạm điều khoản dịch vụ
Các công cụ thu thập dữ liệu web vốn dĩ dễ bị lỗi vì cấu trúc HTML thay đổi mà không báo trước: hãy xây dựng khả năng phục hồi bằng các bộ chọn dự phòng, xác thực kết quả (cảnh báo nếu không tìm thấy mục nào) và ghi nhật ký HTML thô để bạn có thể nhanh chóng cập nhật các bộ chọn khi chúng bị lỗi
AI vượt trội ở phần tẻ nhạt nhất của việc thu thập dữ liệu — tìm ra các bộ chọn CSS: dán HTML vào AI, mô tả dữ liệu bạn cần và AI sẽ xác định chính xác những bộ chọn và viết code trích xuất
Nguồn tin: Quantrimang.com
Ý kiến bạn đọc
Những tin mới hơn
 Xử lý dữ liệu với pandas (09/06/2026)
Xử lý dữ liệu với pandas (09/06/2026)  Prompt dùng Gemini phân tích cấu trúc video bất kỳ (09/06/2026)
Prompt dùng Gemini phân tích cấu trúc video bất kỳ (09/06/2026)  Mẹo nhập Context hiệu quả trong Cursor (09/06/2026)
Mẹo nhập Context hiệu quả trong Cursor (09/06/2026)  Hướng dẫn tạo vòng quay gọi tên học sinh (09/06/2026)
Hướng dẫn tạo vòng quay gọi tên học sinh (09/06/2026)  TOP tiện ích mở rộng AI tốt nhất cho Google Chrome (09/06/2026)
TOP tiện ích mở rộng AI tốt nhất cho Google Chrome (09/06/2026)  Xây dựng Production Page trong phát triển frontend với AI (09/06/2026)
Xây dựng Production Page trong phát triển frontend với AI (09/06/2026)  TOP công cụ AI hỗ trợ viết luận văn, nghiên cứu khoa học (09/06/2026)
TOP công cụ AI hỗ trợ viết luận văn, nghiên cứu khoa học (09/06/2026)  Hướng dẫn tạo ảnh minh họa thơ, truyện kiểu sách lật (09/06/2026)
Hướng dẫn tạo ảnh minh họa thơ, truyện kiểu sách lật (09/06/2026)  Tự động hóa file và thư mục bằng Python với AI (09/06/2026)
Tự động hóa file và thư mục bằng Python với AI (09/06/2026)  Top 5 mô hình AI viết code nhỏ gọn có thể chạy cục bộ (10/06/2026)
Top 5 mô hình AI viết code nhỏ gọn có thể chạy cục bộ (10/06/2026) Những tin cũ hơn
 Cách tạo chỉ mục codebase trong Cursor (09/06/2026)
Cách tạo chỉ mục codebase trong Cursor (09/06/2026)  TOP công cụ phát hiện nội dung AI chính xác nhất (09/06/2026)
TOP công cụ phát hiện nội dung AI chính xác nhất (09/06/2026)  Tích hợp API trong tự động hóa Python với AI (09/06/2026)
Tích hợp API trong tự động hóa Python với AI (09/06/2026)  Hướng dẫn tạo ảnh chân dung chibi 3D phiên bản thu nhỏ (09/06/2026)
Hướng dẫn tạo ảnh chân dung chibi 3D phiên bản thu nhỏ (09/06/2026)  Prompt tạo ảnh chân dung nữ siêu thực bằng AI (09/06/2026)
Prompt tạo ảnh chân dung nữ siêu thực bằng AI (09/06/2026)  TOP công cụ AI giải Toán tốt nhất nên thử (09/06/2026)
TOP công cụ AI giải Toán tốt nhất nên thử (09/06/2026)  Hướng dẫn tách nền ảnh trên ChatGPT chuyên nghiệp (09/06/2026)
Hướng dẫn tách nền ảnh trên ChatGPT chuyên nghiệp (09/06/2026)  Cách tạo Storybook truyện tranh bằng Canva AI (09/06/2026)
Cách tạo Storybook truyện tranh bằng Canva AI (09/06/2026)  Cách sử dụng Zapier Forms: Thu thập dữ liệu và kích hoạt workflow ngay lập tức
Cách sử dụng Zapier Forms: Thu thập dữ liệu và kích hoạt workflow ngay lập tức
 Thêm dữ liệu phi cấu trúc làm nguồn kiến thức cho Copilot Studio agent
Thêm dữ liệu phi cấu trúc làm nguồn kiến thức cho Copilot Studio agent
 Cách tắt tính năng AI của Google Chrome trên máy tính
Cách tắt tính năng AI của Google Chrome trên máy tính
 Prompt tạo ảnh Low Poly 3D hiện đại bằng AI
Prompt tạo ảnh Low Poly 3D hiện đại bằng AI
Prompt tạo ảnh Low Poly 3D hiện đại bằng AI
Prompt tạo ảnh Low Poly 3D hiện đại bằng AI
 Prompt AI biến ảnh thành tranh hoạt hình doodle cực đáng yêu
Prompt AI biến ảnh thành tranh hoạt hình doodle cực đáng yêu
 Cách bật hoặc tắt AI cho Autofill trên Microsoft Edge
Cách bật hoặc tắt AI cho Autofill trên Microsoft Edge
 Tìm hiểu về YandexGPT: Nền tảng AI của Nga dành cho doanh nghiệp
Tìm hiểu về YandexGPT: Nền tảng AI của Nga dành cho doanh nghiệp
 Cách sử dụng Gemini API
Cách sử dụng Gemini API
 99+ Prompt tạo báo cáo Telesales theo ngày, tuần, tháng
99+ Prompt tạo báo cáo Telesales theo ngày, tuần, tháng
 5 dự án thú vị giúp bạn khám phá sức mạnh của OpenAI Codex
5 dự án thú vị giúp bạn khám phá sức mạnh của OpenAI Codex
 TOP công cụ AI thiết kế website tốt nhất
TOP công cụ AI thiết kế website tốt nhất
 Prompt chèn phụ đề cho video trên Gemini
Prompt chèn phụ đề cho video trên Gemini
 Cách sử dụng lệnh /goal trong Claude Code cho các workflow hoàn toàn tự động
Cách sử dụng lệnh /goal trong Claude Code cho các workflow hoàn toàn tự động
 TOP công cụ AI tạo website thương mại điện tử tốt nhất
TOP công cụ AI tạo website thương mại điện tử tốt nhất
 Prompt tạo ảnh Polaroid hoài cổ cực đẹp bằng AI
Prompt tạo ảnh Polaroid hoài cổ cực đẹp bằng AI
 TOP nền tảng AI Workspace tốt nhất
TOP nền tảng AI Workspace tốt nhất
 Prompt tạo hình minh họa Vector tối giản hiện đại bằng AI
Prompt tạo hình minh họa Vector tối giản hiện đại bằng AI
 Karaoke Liều thuốc đắng -Khánh Đơn
Karaoke Liều thuốc đắng -Khánh Đơn
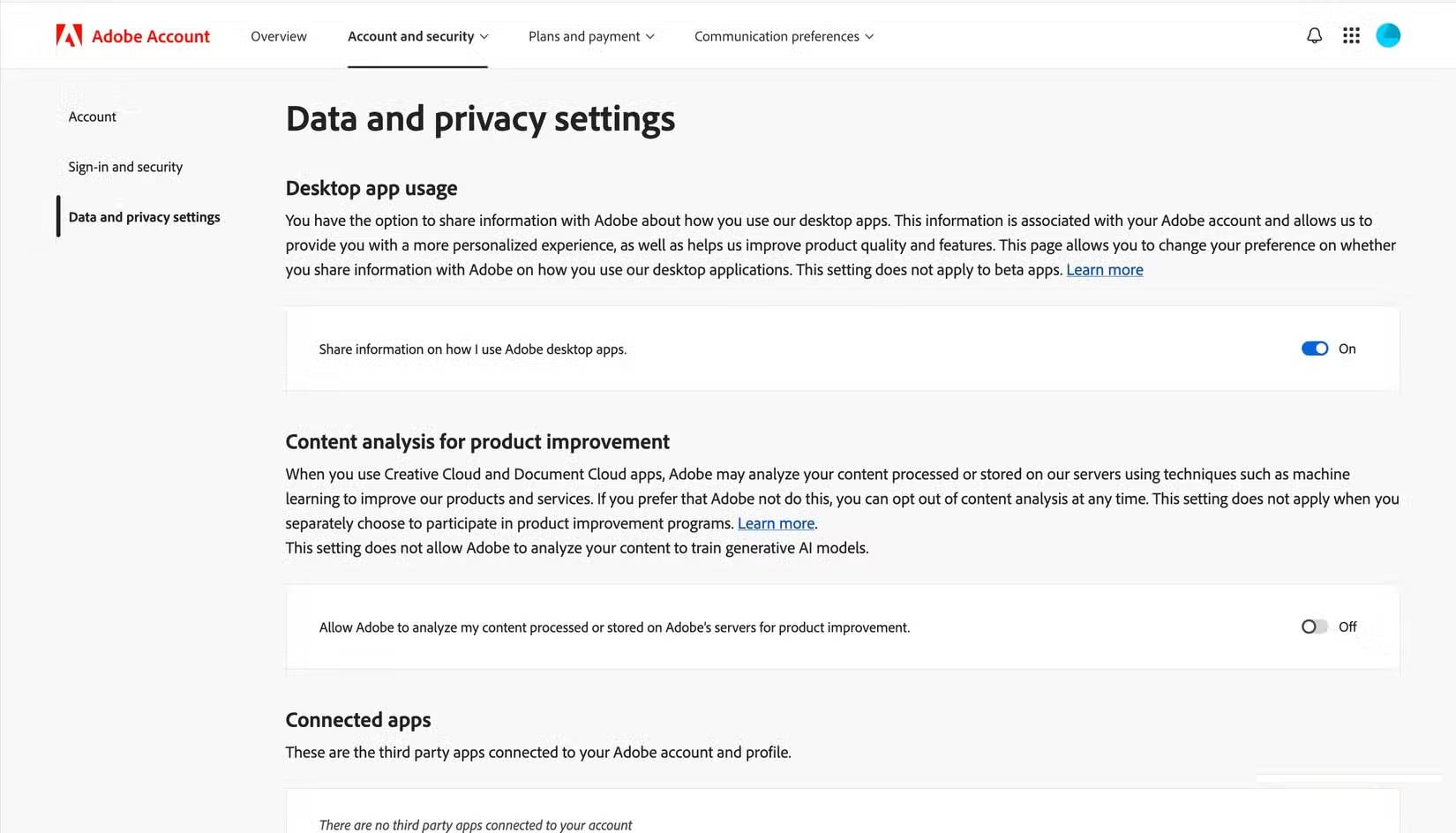 Cách chặn sử dụng dữ liệu cá nhân để huấn luyện AI
Cách chặn sử dụng dữ liệu cá nhân để huấn luyện AI