Thông tin liên hệ
- 036.686.3943
- admin@nguoicodonvn2008.info
Sự bùng nổ của các mô hình ngôn ngữ lớn (LLM) như GPT-4, Llama hay Claude đang thay đổi toàn bộ thế giới trí tuệ nhân tạo. Những mô hình này có thể viết code, trả lời câu hỏi, tóm tắt tài liệu với độ chính xác đáng kinh ngạc.
Với các nhà khoa học dữ liệu, đây là thời kỳ cực kỳ thú vị, nhưng đồng thời cũng đặt ra một thách thức lớn: hiệu suất của các mô hình AI phụ thuộc trực tiếp vào chất lượng dữ liệu .
Trong khi phần lớn sự chú ý tập trung vào mô hình, mạng nơ-ron hay cơ chế attention, thì data engineering mới chính là yếu tố cốt lõi của kỷ nguyên LLM . Những nguyên tắc quản lý dữ liệu truyền thống không bị thay thế, mà đang được nâng cấp.
Trong bài viết này, chúng ta sẽ tìm hiểu cách vai trò của dữ liệu đang thay đổi, các pipeline quan trọng trong quá trình huấn luyện và suy luận, cũng như những kiến trúc mới như RAG đang định hình cách xây dựng ứng dụng AI hiện đại.

Trước đây, data engineering chủ yếu phục vụ Business Intelligence (BI). Mục tiêu là đưa dữ liệu từ hệ thống vận hành vào data warehouse để trả lời những câu hỏi như: “Doanh số quý trước là bao nhiêu?”
Dữ liệu trong BI thường có cấu trúc rõ ràng, được sắp xếp theo hàng và cột.
Tuy nhiên, kỷ nguyên LLM yêu cầu một cách tiếp cận khác. Thay vì chỉ xử lý dữ liệu có cấu trúc, giờ đây chúng ta phải xử lý dữ liệu phi cấu trúc như:
Văn bản trong PDF
Bản ghi cuộc gọi khách hàng
Email nội bộ
Code trong GitHub
Tài liệu nội bộ doanh nghiệp
Mục tiêu không còn chỉ là lưu trữ dữ liệu, mà là chuyển đổi dữ liệu để AI có thể hiểu và suy luận .
Điều này dẫn đến nhu cầu xây dựng pipeline dữ liệu mới phục vụ ba giai đoạn chính:
Huấn luyện và fine-tuning
Suy luận và truy xuất thông tin
Đánh giá và giám sát
Trước khi một mô hình AI có thể hoạt động hiệu quả, nó phải được huấn luyện trên lượng dữ liệu khổng lồ. Đây là nơi data engineering đóng vai trò cực kỳ quan trọng.
Thứ nhất là quy mô dữ liệu. LLM học bằng cách nhận diện mẫu thống kê trong dữ liệu. Để hiểu ngữ pháp, logic và ngữ cảnh, mô hình cần tiếp xúc với hàng nghìn tỷ token. Điều này đòi hỏi xử lý dữ liệu ở quy mô petabyte từ các nguồn như Common Crawl, GitHub hay tài liệu khoa học.
Thứ hai là độ đa dạng của dữ liệu. Một mô hình chỉ được huấn luyện bằng tài liệu pháp lý sẽ không thể viết thơ tốt. Vì vậy, dữ liệu cần được lấy từ nhiều lĩnh vực khác nhau để đảm bảo khả năng tổng quát hóa.
Thứ ba là chất lượng dữ liệu. Internet chứa rất nhiều nội dung spam, thông tin sai lệch hoặc dữ liệu trùng lặp. Vì vậy, pipeline dữ liệu cần:
Loại bỏ nội dung trùng lặp
Lọc ngôn ngữ không mong muốn
Loại bỏ nội dung độc hại
Theo dõi nguồn dữ liệu (data lineage)
Nguyên tắc quan trọng nhất là: Mô hình AI chỉ tốt khi dữ liệu huấn luyện đủ tốt .
Phần lớn doanh nghiệp không tự huấn luyện mô hình từ đầu. Thay vào đó, họ kết nối mô hình có sẵn với dữ liệu riêng. Đây chính là lúc kiến trúc RAG (Retrieval-Augmented Generation) phát huy vai trò.
RAG giúp giải quyết vấn đề lớn của LLM: dữ liệu bị “đóng băng” tại thời điểm huấn luyện. Nếu hỏi về sự kiện mới, mô hình sẽ không biết.
Với RAG, mô hình có thể truy xuất dữ liệu theo thời gian thực.
Quy trình RAG thường diễn ra như sau:
Trước tiên, dữ liệu nội bộ như PDF, Slack hoặc tài liệu nội bộ được đưa vào pipeline. Sau đó dữ liệu được chia thành các đoạn nhỏ để phù hợp với giới hạn context window.
Mỗi đoạn dữ liệu được chuyển thành vector thông qua embedding model. Các vector này được lưu trong vector database.
Khi người dùng đặt câu hỏi, hệ thống chuyển câu hỏi thành vector, tìm kiếm dữ liệu tương tự và gửi dữ liệu liên quan cho LLM để tạo câu trả lời.
Hiệu quả của RAG phụ thuộc trực tiếp vào pipeline dữ liệu. Nếu dữ liệu bị chia sai hoặc embedding không phù hợp, kết quả sẽ không chính xác.
Kỷ nguyên LLM cũng kéo theo sự thay đổi trong hệ sinh thái công nghệ dữ liệu.
Vector database trở thành thành phần cốt lõi. Khác với database truyền thống tìm kiếm theo từ khóa, vector database tìm kiếm theo ngữ nghĩa.
Một số vector database phổ biến gồm:
Pinecone
Weaviate
Milvus
PostgreSQL với pgvector
Ngoài ra, các framework orchestration giúp kết nối pipeline và LLM cũng ngày càng phổ biến. Ví dụ như:
LangChain
LlamaIndex
Các công cụ ETL truyền thống như Spark vẫn đóng vai trò quan trọng trong xử lý dữ liệu lớn.
Điểm quan trọng là stack mới không thay thế stack cũ, mà mở rộng thêm khả năng AI.
Khác với machine learning truyền thống, việc đánh giá LLM phức tạp hơn. Nếu mô hình tạo ra đoạn văn, làm sao biết nó đúng hay sai?
Đây là lúc observability trở nên quan trọng. Data engineer cần theo dõi toàn bộ pipeline để xác định lỗi.
Một hệ thống RAG trả lời sai có thể do:
Thiếu dữ liệu
Lỗi truy xuất
LLM tạo nội dung sai
Để giải quyết, hệ thống cần ghi lại:
Câu hỏi người dùng
Dữ liệu truy xuất
Câu trả lời cuối cùng
Thông qua phân tích dữ liệu này, hệ thống có thể cải thiện liên tục.
Chúng ta đang bước vào thời kỳ AI trở thành giao diện chính để tương tác với dữ liệu. Điều này khiến data engineering trở nên quan trọng hơn bao giờ hết.
Các kỹ năng xử lý dữ liệu, làm sạch dữ liệu và xây dựng pipeline đang trở thành nền tảng của AI hiện đại.
Nếu bạn là data scientist, việc hiểu data engineering trong kỷ nguyên LLM sẽ giúp bạn không chỉ bắt kịp xu hướng mà còn xây dựng nền tảng cho tương lai.
Nguồn tin: Quantrimang.com
Ý kiến bạn đọc
Những tin mới hơn
 6 Web API miễn phí mà mọi lập trình viên AI và “vibe coder” nên biết (11/04/2026)
6 Web API miễn phí mà mọi lập trình viên AI và “vibe coder” nên biết (11/04/2026)  Google AI Edge Eloquent: Ứng dụng ghi âm mới của Google có gì đặc biệt? (11/04/2026)
Google AI Edge Eloquent: Ứng dụng ghi âm mới của Google có gì đặc biệt? (11/04/2026)  Hướng dẫn sử dụng Genspark AI tạo slide cực đẹp (12/04/2026)
Hướng dẫn sử dụng Genspark AI tạo slide cực đẹp (12/04/2026)  Cuộc sống sẽ dễ chịu hơn, nếu ta không mong đợi vào điều gì (13/04/2026)
Cuộc sống sẽ dễ chịu hơn, nếu ta không mong đợi vào điều gì (13/04/2026)  Tạo game luyện trí nhớ cho học sinh trên ESL Games Plus (13/04/2026)
Tạo game luyện trí nhớ cho học sinh trên ESL Games Plus (13/04/2026)  Hướng dẫn tạo phiếu bài tập từ ảnh trên Iron AI (13/04/2026)
Hướng dẫn tạo phiếu bài tập từ ảnh trên Iron AI (13/04/2026)  Cách tạo sổ ghi chú mới ngay trong Gemini (13/04/2026)
Cách tạo sổ ghi chú mới ngay trong Gemini (13/04/2026)  Cách tạo video chú mèo máy mở đầu tiết học trên Gemini (13/04/2026)
Cách tạo video chú mèo máy mở đầu tiết học trên Gemini (13/04/2026)  Lên kế hoạch sản xuất video hoàn chỉnh với sự trợ giúp từ AI (13/04/2026)
Lên kế hoạch sản xuất video hoàn chỉnh với sự trợ giúp từ AI (13/04/2026)  Prompt tạo bài tập và phiếu bài tập trên NotebookLM (13/04/2026)
Prompt tạo bài tập và phiếu bài tập trên NotebookLM (13/04/2026) Những tin cũ hơn
Hướng dẫn sử dụng Genspark AI tạo slide cực đẹp (10/04/2026)  Thiết kế infographic trên Gamma AI chỉ bằng câu lệnh (10/04/2026)
Thiết kế infographic trên Gamma AI chỉ bằng câu lệnh (10/04/2026)  Hướng dẫn dùng Codia AI trên Canva tạo thiết kế cực nhanh (10/04/2026)
Hướng dẫn dùng Codia AI trên Canva tạo thiết kế cực nhanh (10/04/2026)  7 mẹo dùng ChatGPT để tự động hóa công việc dữ liệu (10/04/2026)
7 mẹo dùng ChatGPT để tự động hóa công việc dữ liệu (10/04/2026)  Cách sử dụng ChatGPT để phát hiện các trò lừa đảo phishing (10/04/2026)
Cách sử dụng ChatGPT để phát hiện các trò lừa đảo phishing (10/04/2026) 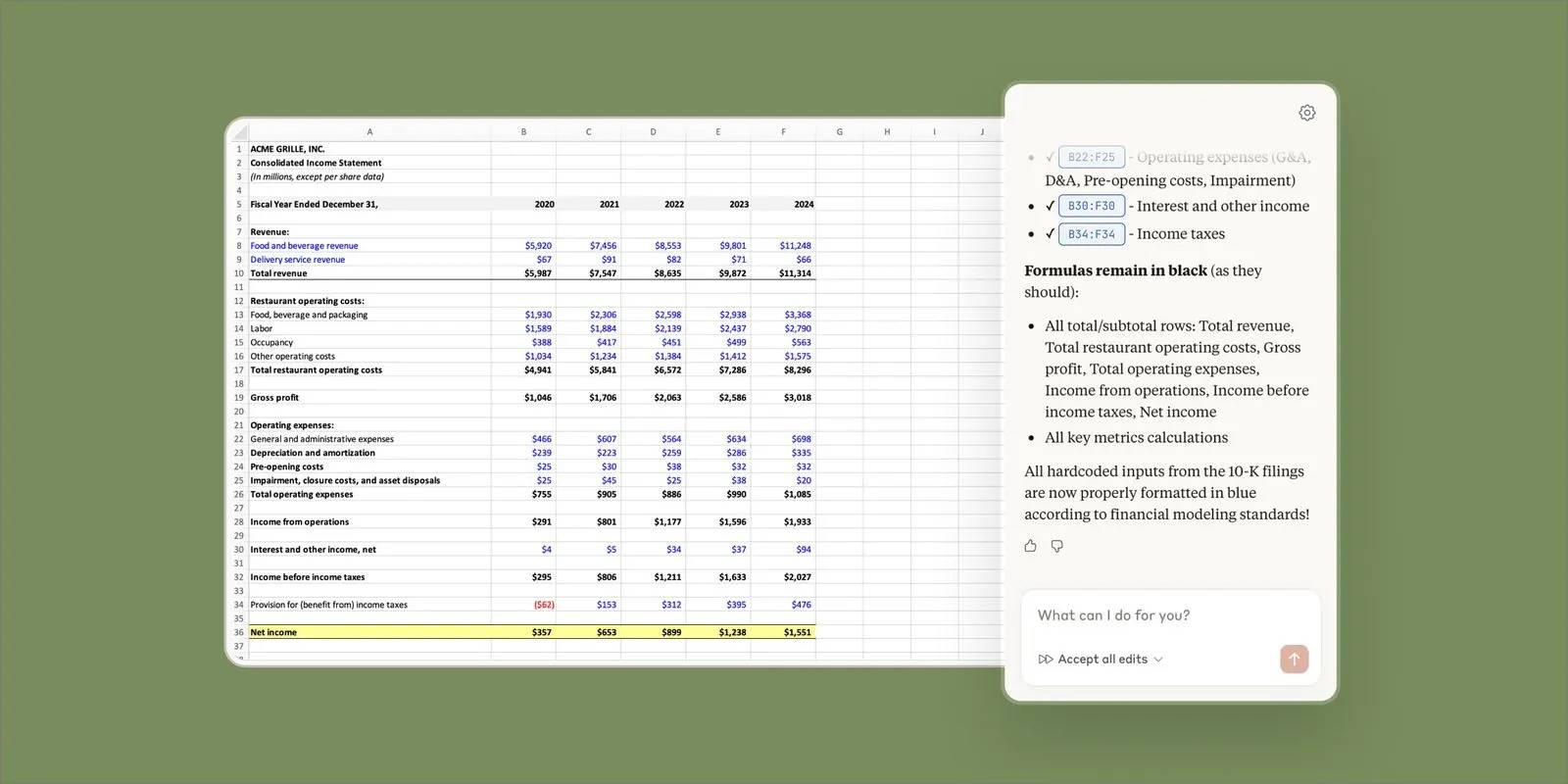 Cách sử dụng Claude AI để viết công thức Excel tức thì (10/04/2026) Cách sử dụng Claude AI để viết công thức Excel tức thì (10/04/2026)
Cách sử dụng Claude AI để viết công thức Excel tức thì (10/04/2026) Cách sử dụng Claude AI để viết công thức Excel tức thì (10/04/2026)  Cách chia sẻ NotebookLM công khai (10/04/2026)
Cách chia sẻ NotebookLM công khai (10/04/2026)  5 mẹo biến OpenAI Codex thành AI coding agent mạnh mẽ hơn (10/04/2026)
5 mẹo biến OpenAI Codex thành AI coding agent mạnh mẽ hơn (10/04/2026)  Prompt tạo câu hỏi gợi mở và kiểm tra trên NotebookLM (10/04/2026)
Prompt tạo câu hỏi gợi mở và kiểm tra trên NotebookLM (10/04/2026)  Prompt tạo chân dung hai nửa cảm xúc khuôn mặt cực điện ảnh
Prompt tạo chân dung hai nửa cảm xúc khuôn mặt cực điện ảnh
 Hướng dẫn tạo video từ hình ảnh trên Magi AI
Hướng dẫn tạo video từ hình ảnh trên Magi AI
 Cách sử dụng Permission Prompt /fewer của Claude Code để xây dựng danh sách cho phép tùy chỉnh
Cách sử dụng Permission Prompt /fewer của Claude Code để xây dựng danh sách cho phép tùy chỉnh
 DeepL vs ChatGPT: Công cụ AI nào tốt hơn?
DeepL vs ChatGPT: Công cụ AI nào tốt hơn?
 Cách ghép file PDF, gộp và nối nhiều file PDF thành một file duy nhất
Cách ghép file PDF, gộp và nối nhiều file PDF thành một file duy nhất
 Hướng dẫn dùng Gemini tóm tắt nội dung video YouTube
Hướng dẫn dùng Gemini tóm tắt nội dung video YouTube
 Prompt AI tạo tranh doodle phong cách Hàn Quốc cực dễ thương
Prompt AI tạo tranh doodle phong cách Hàn Quốc cực dễ thương
 Cách thay đổi giọng văn trên Notion
Cách thay đổi giọng văn trên Notion
 Claude Code Loop là gì? Cách lên lịch các tác vụ định kỳ cho AI agent
Claude Code Loop là gì? Cách lên lịch các tác vụ định kỳ cho AI agent
 Hướng dẫn yêu cầu Notion AI tạo lại câu trả lời
Hướng dẫn yêu cầu Notion AI tạo lại câu trả lời
 Karaoke Thêm một lần đau- Beat Midi
Karaoke Thêm một lần đau- Beat Midi
 Prompt AI tạo mô hình 3D isometric siêu dễ thương chỉ với một dòng lệnh
Prompt AI tạo mô hình 3D isometric siêu dễ thương chỉ với một dòng lệnh
 Những lời chúc đầu tuần hay cho cả 7 ngày may mắn
Những lời chúc đầu tuần hay cho cả 7 ngày may mắn
 Ornith-1.0 là gì? Tìm hiểu mô hình AI lập trình mã nguồn mở với cơ chế "tự xây dựng quy trình làm việc"
Ornith-1.0 là gì? Tìm hiểu mô hình AI lập trình mã nguồn mở với cơ chế "tự xây dựng quy trình làm việc"
 Sự khác biệt giữa Zapier MCP, Zapier SDK và Zapier CLI
Sự khác biệt giữa Zapier MCP, Zapier SDK và Zapier CLI
 12 cài đặt Claude Code bạn nên kích hoạt ngay bây giờ
12 cài đặt Claude Code bạn nên kích hoạt ngay bây giờ
 TOP trợ lý AI sắp xếp lịch tốt nhất
TOP trợ lý AI sắp xếp lịch tốt nhất
 8 framework Agentic AI đáng chú ý nhất năm 2026 mà lập trình viên AI nên biết
8 framework Agentic AI đáng chú ý nhất năm 2026 mà lập trình viên AI nên biết
 Prompt tạo giấy mời họp phụ huynh đầu năm
Prompt tạo giấy mời họp phụ huynh đầu năm